The AI research landscape is currently one of the most dynamic and vibrant fields, showing no signs of slowing down anytime soon. Among the myriad developments, the Llamas have managed to steal the spotlight, thanks to Meta’s LLAMA (Large Language Model Meta AI) and Jerry Liu’s LlamaIndex (formerly GPT Index). These innovations have stirred considerable interest in the community, especially with their potential to revolutionise various applications.
In this blog post, we’ll delve into the role of LlamaIndex, an essential data framework for LLM applications, in streamlining the integration and utilisation of LLMs with custom, private, or proprietary data.
But before diving into its intricacies, let’s briefly introduce this data framework.
LlamaIndex – Brief Overview
Llama Index is a comprehensive data framework that facilitates the ingestion, structuring, and using publicly available or private data on which you can train your LLM.
This framework bridges the gap between your data and the large language model. It helps developers in various stages of working with data and LLMs, such as:
- Ingesting Data – LlamaIndex helps get the data into the system from its source.
- Structuring Data – It helps organise the data so the language models can easily understand.
- Retrieval of Data – It allows you to find and fetch the right data when needed.
- Integration of Data – It helps you to combine your data with various app frameworks.
Now, let’s explore how you can use LlamaIndex to supercharge your applications with the power of large language models of your choice.
Getting Started with LlamaIndex
LlamaIndex provides a single interface to many different LLMs, allowing you to pass in any LLM you choose to any pipeline stage. It could be as simple as this:
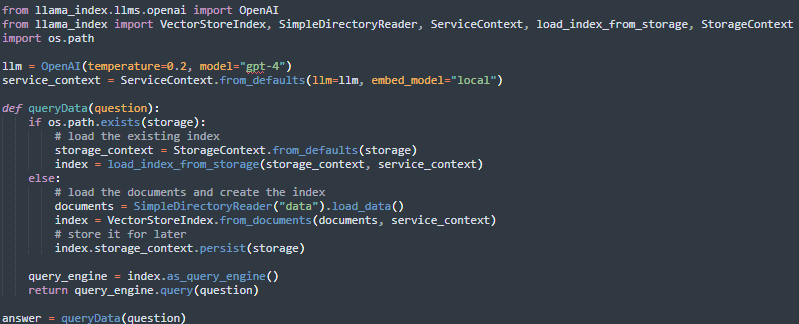
Approaches to leverage an LLM for custom data
We understand your business is aflood with custom data integrated into diverse applications such as Salesforce, Slack, and Notion, and data stored in personal files. You can leverage LLMs for your business-specific data using several approaches, as discussed below.
Fine-tuning
One such approach, fine-tuning, involves adjusting the model’s weights to incorporate insights from specific datasets. However, this process has its share of challenges. It requires much work to prepare the data and undergo a challenging optimisation process, which calls for a certain level of expertise in machine learning. Also, it would help if you considered the financial implications of dealing with large datasets.
For example, the fine-tuned model Llama-2-chat uses publicly available instruction datasets and over 1 million human annotations. It uses reinforcement learning from human feedback (RHLF) to ensure safety and usefulness (as shown in the image below).
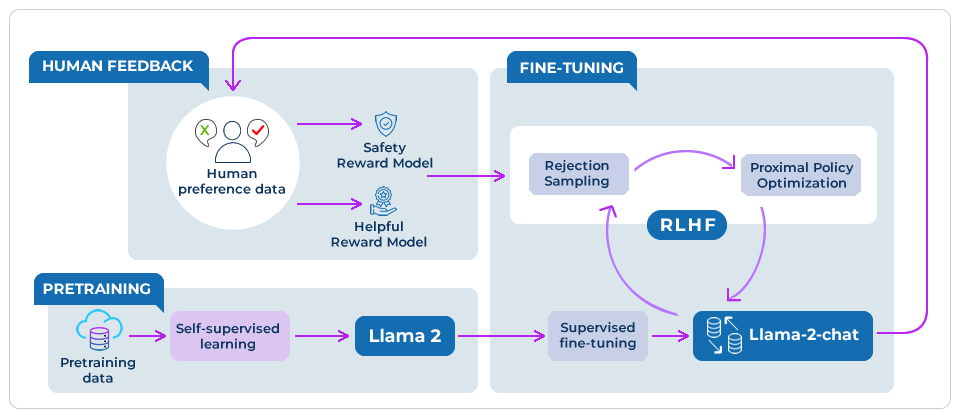
Source: Meta AI
In-context learning
Another alternative could be in-context learning, which prioritises crafting inputs and prompts to provide the LLM with the required context to generate accurate outputs. This method reduces the necessity for extensive model retraining, providing a more efficient and accessible way to incorporate private data.
However, this approach has drawbacks, too. It would be best if you had expertise in prompt engineering. Also, regarding reliability and precision, in-context learning may need to be on par with fine-tuning, particularly when handling technical data.
The model’s initial training on diverse internet text doesn’t ensure it understands specific terms or situations, which can result in wrong or unrelated responses (aka hallucinations). This is a big issue, especially when the data comes from a specialised field or industry.
Retrieval-Augmented Generation (RAG)
RAG extends LLMs’ already powerful capabilities to specific domains or your organisation’s internal knowledge base without requiring the model to be retrained (see image below).
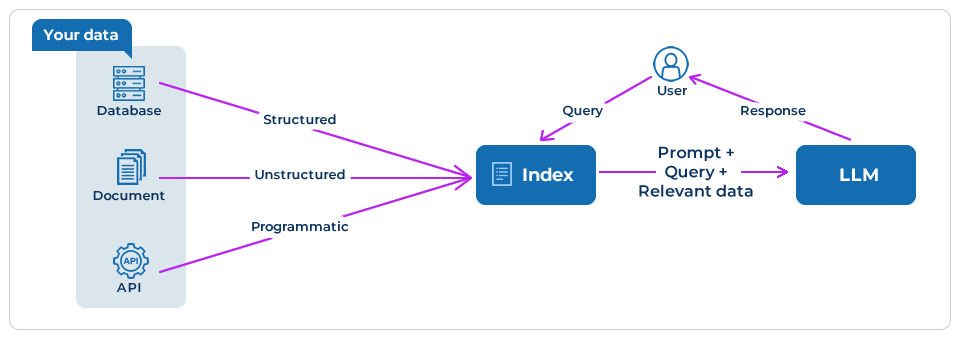
Source: LlamaIndex
In RAG, your data is indexed, i.e., loaded and prepared for user queries. When you put your queries, the index filters your data to find the most relevant information. Then, it uses this context to help LLM answer your question.
Key Steps for Building an LLM application
Loading Data
You can fetch data from various sources such as text, PDFs, databases, or APIs. LlamaIndex provides numerous connectors through LlamaHub to access diverse data sources.
The most basic method for importing data from local files into LlamaIndex is through SimpleDirectoryReader. For more advanced or production scenarios, though, we recommend utilising one of the various Readers on LlamaHub. SimpleDirectoryReader is an easy starting point.
LlamaParse, developed by LlamaIndex, is an API designed to parse and structure files adeptly. It facilitates streamlined data retrieval and context enrichment with LlamaIndex frameworks. Seamlessly integrating with LlamaIndex, LlamaParse enhances the efficiency of file processing and representation within the ecosystem.
Within LlamaHub, integrations include a range of utilities, including Data Loaders, Agent Tools, Llama Packs, and Llama Datasets. These components greatly simplify linking extensive language models with diverse knowledge and data sources, fostering seamless connectivity and accessibility across various platforms and resources.
Transformations
Transformations in LlamaIndex play a pivotal role in effectively processing data. They are functions designed to take a list of nodes as input and produce another list of nodes as output. Each Transformation component, built on the Transformation base class, has synchronous and asynchronous definitions.
These Transformations encompass various operations, such as text splitting, metadata extraction, and node parsing. LlamaIndex provides comprehensive documentation on the usage patterns and modules of Node Parsers, detailing different text splitters like sentence, token, HTML, JSON, and other parser modules.
Moreover, file-based node parsers streamline the process by automatically selecting the appropriate parser for each content type. A common practice involves combining the FlatFileReader with the SimpleFileNodeParser to seamlessly handle different content formats, followed by chaining file-based parsers with text-based ones to ensure accurate text length representation.
Node parsers are a fundamental abstraction within LlamaIndex, breaking down documents into smaller Node objects. Each node represents a distinct chunk of the parent document, inheriting all its attributes, such as metadata, text, and metadata templates. This modular approach facilitates efficient data processing and organisation, enabling users to manage and manipulate data effectively within their workflows.
Integrations
LlamaIndex provides ingestion pipelines that import and process data from various sources, streamlining the consolidation into a centralised storage or analysis system.
In an IngestionPipeline, you can apply transformations to your input data. These transformations process your data; the resulting nodes can be returned or stored in a vector database if provided.
Each combination of a node and its corresponding transformation is cached. This caching system allows subsequent runs, significantly if you save the cache, to reuse the cached results for the same node and transformation combination, thus saving you time.
A typical scenario involves conversing with an LLM about files stored on your computer.
LlamaIndex has developed a command-line interface (CLI) tool to facilitate this interaction. With this tool, you direct it to the files you’ve saved locally, and it handles the rest. The tool ingests these files into a local vector database, enabling a Chat Q&A session right within your terminal.
Tracing and Debugging
Monitoring and debugging, known as observability, are crucial for understanding and improving the inner workings of LLM applications.
LlamaIndex simplifies the development of LLM applications by offering one-click observability. This feature enables you to construct principled LLM applications in real-world settings easily.
A crucial aspect of developing LLM applications over your data, such as RAG systems and agents, is the ability to observe, debug, and evaluate the system comprehensively. With LlamaIndex, you can seamlessly integrate the library with powerful observability and evaluation tools its partners provide.
By configuring variables just once, you gain access to features like viewing LLM and prompt inputs or outputs, ensuring the performance of components like LLMs and embeddings, and examining call traces for both indexing and querying operations.
Evaluation
LlamaIndex helps link your data to your LLM applications. When troubleshooting bugs, sometimes you need a detailed evaluation beyond just looking at traces. LlamaIndex offers tools for this, making it more straightforward to spot issues and get helpful diagnostic signals. It’s closely related to experimentation and tracking experiments.
When creating your LLM application, it’s beneficial to outline a complete evaluation process from start to finish. As you gather data on failures or unusual scenarios, you can refine your understanding of what works and what doesn’t. Then, you can delve deeper into assessing and enhancing individual parts of the system.
Compared to software testing, integration tests are your gold standard for assessing how well different parts of your system work together. Once you begin tweaking individual components, it’s like starting to write unit tests. Both integration and unit tests are equally crucial in ensuring the smooth operation of your LLM application.
Wrapping up
LlamaIndex stands out as an essential framework in data engineering. It offers robust solutions for importing, processing, and managing data from diverse sources.
By simplifying complex tasks into reusable parts, LlamaIndex enables you to concentrate on your specific data needs without worrying about the implementation details.
Combining LlamaIndex with an LLM, we aim to address large-scale data challenges for enterprises. Whether you’re managing or harnessing your data, our solutions provide firm support. They help your organisation gain valuable insights and drive business growth.
Do you want to leverage your data resources for insights? Reach out to our experts today!