Have you ever wondered how search engines know to provide such relevant results, even when your query is vague or doesn’t match the exact wording of the relevant documents? Retrieval augmentation is the secret sauce that makes this possible, revolutionizing how we access and interact with information.

AI models rely heavily on their ability to retrieve and process relevant information efficiently. Retrieval augmentation techniques have emerged as powerful tools to enhance AI capabilities by incorporating external knowledge sources.
In this blog post, we will delve into three prominent retrieval augmentation models: RAG (Retrieval Augmented Generation), RAT (Retrieval Augmented Transformer), and RAR (Retrieval Augmented Reasoning).
We will explore their underlying principles, use cases, and comparative advantages and challenges, equipping you with practical knowledge about these innovative approaches and empowering you to make informed decisions in your AI projects.
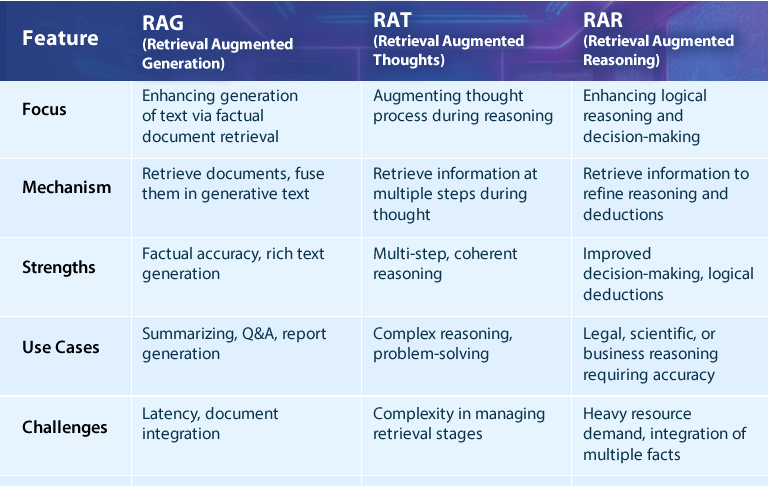
TLDR; Here’s a table that compares three retrieval augmentation models, highlighting their unique approaches, strengths, and potential applications:
Retrieval Augmented Generation (RAG)
Retrieval augmented generation (RAG) is a hybrid model that blends retrieval mechanisms with natural language generation (NLG). This approach, with its practical applications in enabling language models to fetch external data in response to queries and use that information to produce more accurate and relevant answers, directly addresses the limitations of pre-trained language models. This makes the information presented here highly relevant and applicable.
RAG, a model of significant importance in the field of AI, relies on two core components:
- Information Retrieval (IR): The model retrieves relevant documents or pieces of information from a structured or unstructured knowledge base (such as Wikipedia, proprietary databases, or other content repositories).
- Text Generation: The language model processes and integrates the retrieved information into the generated text to provide a coherent response.
Underlying Principles of RAG
- Document Retrieval: When a user asks a question or presents a query, the retrieval model (often based on Dense Passage Retrieval (DPR) or BM25 algorithms) selects the top relevant documents from an indexed knowledge base.
- Fusion into Text Generation: The retrieval system passes the selected documents to the generative model, which plays a crucial role in integrating the information into its decoding process, generating a more refined and accurate response. This step helps the model provide contextually rich answers.
- Response Generation: The generative model produces the final output, fusing both pre-trained knowledge and external data to generate a highly accurate response.
Use Cases of RAG
- Knowledge-Intensive Tasks: RAG is particularly useful for tasks like question answering (QA), requiring factual accuracy. For example, medical or legal queries that need the latest research or case precedents.
- Document Summarization: RAG can summarize essential information from long texts or large datasets by fetching relevant paragraphs or sections of documents.
- Customer Support: RAG-powered models can handle customer queries by retrieving real-time support documentation and combining it with conversational responses.
Advantages of RAG
- Factual Accuracy: RAG models provide responses based on real-time, accurate data pulled from external knowledge sources, ensuring that answers reflect the most current information.
- Dynamic Knowledge: It enables LLMs to operate beyond their pre-training cutoffs, delivering responses based on the latest data rather than static knowledge bases.
- Versatility: The model can be trained on a wide variety of data sources, from proprietary company information to open-source knowledge bases, adapting to different domains.
Challenges of RAG
- Latency: The time taken for document retrieval and integration into the response can introduce delays, particularly when the knowledge base is large or the query is complex.
- Contextual Integration: Successfully blending retrieved documents into coherent, contextually appropriate text can be tricky, particularly when the retrieved documents contain conflicting or overly technical information.
- Scalability: As the volume of data grows, efficiently retrieving and processing information can be computationally intensive.
Retrieval Augmented Thoughts (RAT)
Retrieval Augmented Thoughts (RAT) is an approach that focuses on augmenting the internal reasoning or thought process of a model by retrieving relevant knowledge at different steps in its chain of reasoning. While RAG retrieves information once and uses it to generate a response, RAT retrieves information multiple times during intermediate steps of reasoning, mirroring how humans think by gathering data iteratively to refine their thoughts.
RAT introduces a more structured, multi-stage process where external data is brought in to assist at each stage of reasoning rather than just influencing the final output.
Underlying Principles of RAT
- Iterative Knowledge Retrieval: As the model processes the query, it pauses at different stages to retrieve new information that could enhance its reasoning at each step. This mimics a more stepwise reasoning process.
- Chained Reasoning: The model uses intermediate retrieval steps to refine its thinking. For example, in solving a complex problem, the model may retrieve facts or data that support each step toward the final solution.
- Dynamic Knowledge Injection: The retrieval process is dynamic and adaptive, with the model fetching additional data as needed based on the evolution of its reasoning.
Use Cases of RAT
- Complex Problem Solving: RAT models are beneficial for problems that require step-by-step reasoning, such as mathematical problem solving, hypothesis generation in scientific research, or diagnosing complex technical issues.
- Multi-Step Reasoning Tasks: This could include decision-making processes that require constant adjustment based on new information, such as legal reasoning or strategic planning.
- Chain-of-Thought (CoT) Prompting: In scenarios where tasks require logical sequences, RAT improves the model’s ability to break down problems into manageable steps, enhancing performance on multi-step reasoning tasks.
Advantages of RAT
- Improved Coherence: Since retrieval happens at various reasoning stages, the model can correct or refine its thoughts, leading to more logical and coherent responses. This results in higher accuracy for complex queries.
- Enhanced Interpretability: The multi-step retrieval process provides better transparency into the model’s decision-making or thought process, making it easier to understand how conclusions were reached.
- Supports Complex Reasoning: RAT models are better suited for tasks requiring long-form or deep reasoning than traditional retrieval or generative models.
Challenges of RAT
- Computational Complexity: Iterative retrieval steps can significantly increase computational costs and processing times, especially in real-time applications.
- Data Fragmentation: Retrieving information at each thought stage can introduce fragmentation, making it difficult for the model to consolidate the retrieved information into a single coherent line of reasoning.
- Dependence on Retrieval Quality: The quality of the final outcome relies heavily on the retrieved data’s relevance at each step, making accurate retrieval essential.
Retrieval Augmented Reasoning (RAR)
Retrieval Augmented Reasoning (RAR) builds on the foundation laid by both RAG and RAT but emphasises enhancing the logical reasoning capabilities of AI models. It is tailored for scenarios that demand not just knowledge retrieval or multi-step thought processes but deep logical deductions and decision-making based on factual and contextual data.
RAR goes beyond augmenting intermediate thoughts; it improves the model’s reasoning by injecting relevant knowledge that guides its ability to make sound conclusions or judgments.
Underlying Principles of RAR
- Contextual Knowledge Retrieval: As the model moves through its reasoning process, it retrieves knowledge based on the specific context or logical pathway required to answer the query or solve the problem.
- Reasoning Support: The retrieved information is used to support each logical deduction or conclusion, ensuring that the model’s reasoning is not only accurate but also grounded in verifiable facts.
- Feedback Loops: Some implementations of RAR involve feedback loops where the model evaluates its own reasoning using retrieved knowledge, allowing it to double-check assumptions or recalibrate its reasoning path.
Use Cases of RAR
- Legal and Scientific Reasoning: RAR is ideal for fields requiring precise logical deductions, such as legal analyses or scientific research where decisions are based on facts or case precedents.
- Complex Decision Making: In business or financial contexts, RAR helps make decisions that depend on multi-faceted data inputs and require high-stakes reasoning.
- Hypothesis Testing: RAR can aid in testing hypotheses by retrieving relevant research or data and using it to support or refute a logical progression.
Advantages of RAR
- Enhanced Logical Deduction: RAR models can make sound, logical conclusions by retrieving knowledge tailored to specific reasoning pathways.
- Accurate Decision Making: Decisions made by RAR models are grounded in external facts and knowledge, making them less prone to the “hallucinations” common in purely generative models.
- Proactive Error Correction: The reasoning support provided by external data ensures that errors in logic are detected and corrected earlier in the reasoning process.
Challenges of RAR
- High Resource Demand: Reasoning tasks that require continuous retrieval of facts or external data demand significant computational resources and processing power.
- Data Integration: Integrating retrieved facts seamlessly into complex reasoning processes can be challenging, especially when dealing with contradictory information or highly nuanced topics.
- Scalability: As the complexity of the reasoning tasks increases, so does the complexity of retrieval and integration, making it difficult to scale RAR models for real-time or high-volume applications.

Selecting the Optimal Retrieval Technique
Retrieval augmentation techniques have revolutionized the field of artificial intelligence, enabling models to access and leverage vast amounts of external knowledge. RAG, RAT, and RAR each offer unique advantages and are well-suited for different applications.
By understanding the strengths and limitations of these models, researchers and developers can make informed decisions when selecting the most appropriate approach for their specific tasks. As AI continues to advance, retrieval augmentation techniques will likely play an increasingly important role in driving innovation and solving complex problems.
Retrieval augmentation can transform your business. Want to learn more about how it can help you achieve your goals? Connect with our AI experts today to discuss your needs and explore potential solutions.
